#data preprocessing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
2 notes
·
View notes
Text
Explore These Exciting DSU Micro Project Ideas
Explore These Exciting DSU Micro Project Ideas Are you a student looking for an interesting micro project to work on? Developing small, self-contained projects is a great way to build your skills and showcase your abilities. At the Distributed Systems University (DSU), we offer a wide range of micro project topics that cover a variety of domains. In this blog post, we’ll explore some exciting DSU…
#3D modeling#agricultural domain knowledge#Android#API design#AR frameworks (ARKit#ARCore)#backend development#best micro project topics#BLOCKCHAIN#Blockchain architecture#Blockchain development#cloud functions#cloud integration#Computer vision#Cryptocurrency protocols#CRYPTOGRAPHY#CSS#data analysis#Data Mining#Data preprocessing#data structure micro project topics#Data Visualization#database integration#decentralized applications (dApps)#decentralized identity protocols#DEEP LEARNING#dialogue management#Distributed systems architecture#distributed systems design#dsu in project management
0 notes
Text
Data Preparation and Cleaning using CHAT GPT | Topic 3
https://youtu.be/JwCyeLm5kGo
youtube
#the data channel#chatgpt#prompt engineering#chatgpt for analysis#datacleaning#data preprocessing#Youtube
0 notes
Text
Multi-pulse Waveform Processing
One the most amazing experiences of my PhD project was to develop and employ a particle detector for a particle accelerator at CERN.
This work also involved a quite deal of data preprocessing and analysis, so to determine the efficiency of the detector. It is a great example of how creative data analysis can overcome limitations from the hardware design and improve detection efficiency by up to 40%!
One of my main design philosophy was to build a detector that was as cheap as possible, from salvaged equipment in the laboratory. To overcome limitations from old components, I developed an algorithm to find the timing of the particles using a constant-fractional discrimination technique. This algorithm finds the timing from the rise time of pulse, overcoming artificial increase in particle timing from large pulses.
One of the great advantages of my algorithm is its speed. While some will fit a special function to the entire pulse in the waveform, my algorithm takes advantage of the rise time being linear to fit a straight line to it.
My algorithm not only improved the timing measurements by 40%, as it was so efficient that it could be incorporated to the on-the-fly analysis, to maximize the quality of the data being acquired. Every spill in a beam line is precious, so we must ensure the quality of the data is maximal!
Later, the algorithm was adapted to extract the timing information for several pulses on a waveform, not only one.
0 notes
Text
Multi-pulse Waveform Analysis
One the most amazing experiences of my PhD project was to develop and employ a particle detector for a particle accelerator at CERN.
This work also involved a quite deal of data preprocessing and analysis, so to determine the efficiency of the detector. It is a great example of how creative data analysis can overcome limitations from the hardware design and improve detection efficiency by up to 40%!
One of my main design philosophy was to build a detector that was as cheap as possible, from salvaged equipment in the laboratory. To overcome limitations from old components, I developed an algorithm to find the timing of the particles using a constant-fractional discrimination technique. This algorithm finds the timing from the rise time of pulse, overcoming artificial increase in particle timing from large pulses.
One of the great advantages of my algorithm is its speed. While some will fit a special function to the entire pulse in the waveform, my algorithm takes advantage of the rise time being linear to fit a straight line to it.
My algorithm not only improved the timing measurements by 40%, as it was so efficient that it could be incorporated to the on-the-fly analysis, to maximize the quality of the data being acquired. Every spill in a beam line is precious, so we must ensure the quality of the data is maximal!
Later, the algorithm was adapted to extract the timing information for several pulses on a waveform, not only one.
0 notes
Text
AI-Powered Personalization: How Machine Learning Is Revolutionizing Customer Experience

In a world where customer experience is paramount, businesses are turning to AI-powered personalization to create truly tailored interactions. Machine learning algorithms are revolutionizing the way companies understand and engage with their customers, leading to higher satisfaction rates and increased loyalty. Join us as we explore the cutting-edge technology behind AI-powered personalization and how it’s reshaping the future of customer experience.
Introduction To AI-Powered Personalization
In an increasingly digital world, businesses face the challenge of standing out in a sea of competition and capturing the attention of their target audience. Enter AI-powered personalization—a game-changing technology that enables businesses to deliver tailored experiences that resonate with individual customers on a deeper level than ever before. In this blog, we’ll explore the fundamentals of AI-powered personalization, its benefits, and its potential to revolutionize customer experiences.
At its core, AI-powered personalization is the use of artificial intelligence (AI) algorithms to analyze data and deliver customized experiences to users. By leveraging machine learning techniques, businesses can gain insights into customer preferences, behaviors, and needs, allowing them to tailor content, recommendations, and interactions to each individual user.
AI-powered personalization works by analyzing large volumes of data collected from various sources, such as customer interactions, browsing history, purchase behavior, and demographic information. Machine learning algorithms then use this data to identify patterns, predict future behaviors, and make personalized recommendations or decisions.
For example, an e-commerce retailer may use AI-powered personalization to recommend products based on a customer’s past purchases, browsing history, and preferences. Similarly, a streaming service may use AI algorithms to curate personalized playlists or movie recommendations based on a user’s viewing history and preferences.
What Is Machine Learning?
In an era dominated by technology and data, the term “machine learning” has become increasingly prevalent. But what exactly is machine learning, and how does it work? In this guide, we’ll delve into the fundamentals of machine learning, explore its applications, and shed light on its transformative potential.
At its core, machine learning is a subset of artificial intelligence (AI) that enables computers to learn from data and make predictions or decisions without being explicitly programmed to do so. Instead of relying on predefined rules and instructions, machine learning algorithms use statistical techniques to identify patterns in data and make intelligent decisions or predictions.
How Machine Learning Works
Machine learning algorithms learn from experience, iteratively improving their performance over time as they are exposed to more data. The process typically involves several key steps:
Data Collection: The first step in any machine learning project is to gather relevant data from various sources. This data may include structured data (e.g., databases, spreadsheets) or unstructured data (e.g., text, images, videos).
Data Preprocessing: Once the data is collected, it needs to be cleaned, processed, and prepared for analysis. This may involve tasks such as removing duplicates, handling missing values, and normalizing numerical features.
Model Training: In this step, machine learning models are trained on the prepared data to learn patterns and relationships. This is done by feeding the data into the model and adjusting its parameters to minimize the difference between predicted and actual outcomes.
Evaluation and Validation: After training the model, it is evaluated using a separate set of data called the validation or test set. This helps assess the model’s performance and identify any issues such as overfitting or underfitting.
Model Deployment: Once the model is trained and validated, it can be deployed into production environments to make predictions or decisions in real-time. This may involve integrating the model into existing software systems or applications.
Types Of Machine Learning
Machine learning can be broadly categorized into three main types:
Supervised Learning: In supervised learning, the model is trained on labeled data, where each input is associated with a corresponding output. The goal is to learn a mapping from inputs to outputs, allowing the model to make predictions on new, unseen data.
Unsupervised Learning: Unsupervised learning involves training the model on unlabeled data, where the goal is to identify patterns or structures within the data. This may include tasks such as clustering similar data points together or dimensionality reduction.
Reinforcement Learning: Reinforcement learning is a type of learning where an agent learns to interact with an environment by taking actions and receiving feedback in the form of rewards or penalties. The goal is to learn a policy that maximizes cumulative rewards over time.
Applications Of Machine Learning
Machine learning has a wide range of applications across various industries, including:
Finance: Predictive analytics for stock market forecasting, fraud detection, and risk assessment.
Healthcare: Disease diagnosis, medical image analysis, drug discovery, and personalized treatment recommendations.
E-commerce: Product recommendations, customer segmentation, and pricing optimization.
Marketing: Customer segmentation, targeted advertising, and churn prediction.
Automotive: Autonomous driving, predictive maintenance, and traffic management.

How Machine Learning Is Revolutionizing Customer Experience
In today’s fast-paced digital world, the customer experience has become a cornerstone of business success. With consumers expecting personalized, seamless interactions across all touchpoints, companies are increasingly turning to machine learning to revolutionize the way they engage with their customers. Let’s delve into how machine learning is reshaping the customer experience landscape:
Hyper-Personalization: Machine learning algorithms analyze vast amounts of customer data to understand preferences, behaviors, and patterns. This allows businesses to deliver hyper-personalized experiences tailored to each individual’s unique needs and interests. Whether it’s recommending products based on past purchases, customizing marketing messages, or personalizing website content, machine learning enables businesses to create connections that resonate on a personal level.
Predictive Insights: Machine learning excels at uncovering hidden patterns and trends within data, enabling businesses to predict future customer behaviors and preferences. By analyzing historical data and identifying correlations, machine learning algorithms can anticipate customer needs, preferences, and potential churn. This empowers businesses to proactively address customer concerns, offer timely recommendations, and deliver personalized experiences that drive engagement and loyalty.
Automated Customer Service: Machine learning-powered chatbots and virtual assistants are transforming the way businesses handle customer inquiries and support requests. By leveraging natural language processing (NLP) and machine learning algorithms, these AI-driven solutions can understand and respond to customer queries in real-time. Whether it’s providing product recommendations, troubleshooting issues, or processing transactions, automated customer service agents enhance efficiency, scalability, and round-the-clock availability.
Fraud Detection and Prevention: Machine learning plays a critical role in detecting and preventing fraudulent activities, such as identity theft, payment fraud, and account takeover. By analyzing transaction data, user behavior patterns, and other relevant variables, machine learning algorithms can identify anomalies and flag suspicious activities in real-time. This enables businesses to mitigate risks, protect sensitive customer information, and uphold trust and security in their interactions.
Personalized Content Recommendations: Machine learning algorithms power content recommendation engines that deliver personalized recommendations across various channels, including websites, mobile apps, and streaming platforms. By analyzing user interactions, viewing history, and engagement metrics, these algorithms can suggest relevant articles, videos, products, or music that align with each individual’s interests and preferences. This not only enhances the user experience but also drives engagement and retention.
Dynamic Pricing and Offer Optimization: Machine learning enables businesses to optimize pricing strategies and promotional offers based on customer segmentation, demand forecasting, and competitive analysis. By analyzing market trends, competitor pricing, and historical sales data, machine learning algorithms can dynamically adjust prices and promotions to maximize revenue and profitability. This agile approach to pricing ensures that businesses remain competitive while maximizing value for customers.
Benefits Of AI-Powered Personalization For Businesses
In today’s hyper-connected world, businesses are constantly seeking innovative ways to connect with their customers and drive growth. One of the most powerful tools in their arsenal is AI-powered personalization. By leveraging the capabilities of artificial intelligence and machine learning, businesses can create tailored experiences that resonate with individual customers on a deeper level than ever before. Let’s explore some of the key benefits that AI-powered personalization brings to businesses:
Enhanced Customer Engagement: Personalization is the key to capturing and retaining customer attention in a crowded marketplace. AI-powered personalization allows businesses to deliver content, recommendations, and offers that are highly relevant to each individual’s preferences, needs, and behaviors. By engaging customers with personalized experiences across multiple touchpoints, businesses can foster deeper connections and drive increased loyalty.
Increased Conversion Rates: Personalized experiences have been shown to significantly increase conversion rates and sales. By presenting customers with products, services, and content that align with their interests and past behaviors, businesses can reduce friction in the purchasing process and make it easier for customers to make buying decisions. Whether it’s recommending related products based on past purchases or tailoring promotions to specific customer segments, AI-powered personalization can drive conversion rates and boost revenue.
Improved Customer Satisfaction: When customers feel understood and valued, they’re more likely to be satisfied with their experiences and remain loyal to a brand. AI-powered personalization enables businesses to anticipate customer needs and deliver proactive support, making interactions more efficient and enjoyable. Whether it’s providing personalized product recommendations, offering relevant content, or resolving customer service inquiries in real-time, personalized experiences leave a lasting impression and drive higher levels of satisfaction.
Optimized Marketing ROI: Traditional marketing approaches often rely on broad demographic targeting and mass messaging, which can lead to wasted resources and missed opportunities. AI-powered personalization enables businesses to optimize their marketing efforts by delivering the right message to the right person at the right time. By analyzing customer data and behavior patterns, businesses can segment their audience more effectively, personalize their messaging, and achieve higher ROI on their marketing spend.
Data-Driven Insights: AI-powered personalization generates a wealth of valuable data that businesses can use to gain insights into customer preferences, behaviors, and trends. By analyzing this data, businesses can identify patterns, uncover actionable insights, and make data-driven decisions to drive business growth. Whether it’s identifying emerging trends, predicting future customer behaviors, or optimizing product offerings, AI-powered personalization provides businesses with a competitive edge in today’s data-driven economy.
Competitive Differentiation: In a competitive marketplace, personalized experiences can be a powerful differentiator that sets businesses apart from their competitors. Customers are increasingly expecting personalized interactions from the brands they engage with, and businesses that fail to deliver risk falling behind. By investing in AI-powered personalization, businesses can differentiate themselves from competitors, strengthen their brand identity, and create a unique value proposition that resonates with customers.
Real Life Examples Of Successful AI-Powered Personalization Challenges And Ethical Considerations Of AI-Powered Personalization
In an era where personalization is king, businesses are increasingly turning to AI-powered solutions to deliver tailored experiences to their customers. However, as we embrace the potential of artificial intelligence to revolutionize the customer experience, it’s important to pause and consider the ethical implications and challenges that come with it. From data privacy concerns to algorithmic biases, here are some of the key challenges and ethical considerations of AI-powered personalization:
Data Privacy and Security: One of the most pressing concerns surrounding AI-powered personalization is the issue of data privacy and security. Personalization relies on vast amounts of data collected from users, including their browsing history, purchase behavior, and demographic information. Ensuring that this data is collected, stored, and used responsibly is paramount to maintaining customer trust. Businesses must be transparent about their data collection practices, obtain consent from users where necessary, and implement robust security measures to protect sensitive information from breaches or unauthorized access.
Algorithmic Bias and Fairness: AI algorithms are only as good as the data they’re trained on, and if that data contains biases, it can result in discriminatory outcomes. Algorithmic bias can manifest in various forms, including racial bias, gender bias, and socioeconomic bias. For example, an e-commerce platform may inadvertently show higher-priced products to users from affluent neighborhoods, perpetuating economic disparities. Addressing algorithmic bias requires careful attention to data selection, preprocessing, and ongoing monitoring to ensure that personalization algorithms are fair and equitable for all users.
Lack of Transparency and Explainability: AI-powered personalization often operates as a “black box,” making it difficult for users to understand how their data is being used to personalize their experiences. Lack of transparency and explainability can erode trust and lead to skepticism about the intentions behind personalized recommendations. Businesses must strive to make their personalization algorithms more transparent and provide users with clear explanations of how their data is being used to tailor their experiences. This includes offering opt-in/opt-out mechanisms for personalization and providing users with control over their data.
Overreliance on Automation: While AI-powered personalization can enhance the customer experience, there’s a risk of overreliance on automation at the expense of human judgment and empathy. Automated personalization algorithms may struggle to understand the nuances of human behavior and emotions, leading to impersonal or tone-deaf interactions. Balancing automation with human intervention is essential to ensure that personalized experiences feel authentic and empathetic. Businesses should invest in training their customer service representatives to complement AI-driven personalization with human touchpoints when needed.
Ethical Dilemmas in Decision-Making: AI-powered personalization raises complex ethical dilemmas around decision-making and autonomy. For example, personalization algorithms may prioritize maximizing engagement or sales metrics without considering the long-term implications for user well-being. This can lead to scenarios where users are nudged towards addictive behaviors or harmful content. Businesses must consider the ethical implications of their personalization strategies and prioritize user well-being over short-term gains. This may involve implementing safeguards such as algorithmic audits, ethical guidelines, and user-centric design principles.
Tips For Implementing AI-Powered Personalization In Your Business
In the digital age, personalized experiences are no longer just a luxury—they’re an expectation. Customers crave interactions that are tailored to their preferences, needs, and behaviors. Fortunately, advancements in artificial intelligence (AI) have made it easier than ever for businesses to deliver hyper-personalized experiences at scale. If you’re looking to harness the power of AI-powered personalization to elevate your business, here are some tips to get you started:
Define Your Objectives: Before diving into AI-powered personalization, take the time to clearly define your objectives. What specific business goals are you hoping to achieve through personalization? Whether it’s increasing conversion rates, improving customer retention, or boosting overall engagement, having a clear understanding of your objectives will guide your personalization efforts and help you measure success.
Understand Your Data: Data is the lifeblood of AI-powered personalization. Take stock of the data you currently have access to, including customer demographics, browsing history, purchase behavior, and interactions across various touchpoints. Identify any gaps in your data collection efforts and take steps to fill them. Additionally, ensure that your data is clean, accurate, and compliant with relevant privacy regulations.
Invest in the Right Technology: Choosing the right technology stack is crucial for successful implementation of AI-powered personalization. Look for AI platforms and tools that are specifically designed for personalization use cases and offer robust features such as machine learning algorithms, predictive analytics, and real-time data processing. Consider factors such as scalability, ease of integration with your existing systems, and vendor support when evaluating potential solutions.
Start Small and Iterate: Implementing AI-powered personalization can be a complex process, so it’s important to start small and iterate over time. Focus on implementing personalization strategies for specific use cases or customer segments where you’re likely to see the greatest impact. As you gather feedback and data, refine your personalization strategies and expand to additional use cases or segments.
Combine Data Science with Domain Expertise: While AI algorithms play a critical role in personalization, they’re most effective when combined with domain expertise and human insights. Collaborate closely with data scientists, marketers, product managers, and other stakeholders to ensure that your personalization efforts are aligned with business goals and customer needs. Leverage domain expertise to interpret AI-generated insights and fine-tune personalization strategies accordingly.
Focus on Transparency and Trust: Building trust with your customers is essential for successful AI-powered personalization. Be transparent about how you’re using customer data to personalize experiences, and provide clear opt-in/opt-out mechanisms for data collection and personalization. Respect customer preferences and privacy preferences, and prioritize security measures to safeguard sensitive data.
Measure and Iterate: Finally, don’t forget to measure the impact of your personalization efforts and iterate based on the results. Track key performance indicators (KPIs) such as conversion rates, engagement metrics, and customer satisfaction scores to gauge the effectiveness of your personalization strategies. Use A/B testing and experimentation to identify what works best for your audience and continuously refine your approach accordingly.
Future Of AI-Powered Personalization
In the ever-evolving landscape of technology, the future of AI-powered personalization is nothing short of awe-inspiring. As we delve deeper into the capabilities of artificial intelligence and machine learning, the possibilities for creating hyper-personalized customer experiences are boundless. Let’s embark on a journey to explore how AI-powered personalization is set to revolutionize the way businesses connect with their customers in the coming years.
Predictive Personalization: Imagine a world where businesses can anticipate your needs and desires before you even realize them yourself. This is the promise of predictive personalization, where AI algorithms analyze vast amounts of data to forecast future behaviors and preferences with unparalleled accuracy. From suggesting products you’re likely to love to preemptively addressing customer service inquiries, predictive personalization will empower businesses to stay one step ahead of their customers’ needs.
Multimodal Personalization: In the future, personalization will extend beyond traditional channels like email and web browsing to encompass a wide range of modalities, including voice, augmented reality, and virtual reality. Picture a scenario where your virtual assistant not only understands your voice commands but also recognizes your tone and mood, adapting its responses accordingly. Similarly, augmented reality experiences tailored to your preferences will transform the way you shop, learn, and explore the world around you.
Hyper-Contextualization: Context is king in the realm of personalization, and future AI systems will excel at understanding the intricate nuances of each individual’s context to deliver truly bespoke experiences. Whether you’re browsing a website from your smartphone while on the go or interacting with a chatbot during a late-night support session, AI-powered personalization will factor in your location, time of day, device type, and other contextual cues to tailor its responses and recommendations.
Ethical Personalization: As AI-powered personalization becomes more pervasive, ensuring ethical use of customer data will be paramount. In the future, businesses will need to prioritize transparency, accountability, and consent when collecting and leveraging customer data for personalization purposes. Striking the right balance between personalization and privacy will be essential to building and maintaining trust with customers in an increasingly data-driven world.
Collaborative Personalization: Collaboration will be key to unlocking the full potential of AI-powered personalization in the future. By partnering with other businesses, sharing anonymized data, and leveraging collective intelligence, organizations can create synergistic ecosystems that deliver even more value to customers. Imagine a network of interconnected AI systems working together to seamlessly personalize experiences across a diverse array of touchpoints and industries.
Continuous Learning and Adaptation: In the future, AI-powered personalization will be a dynamic and iterative process that continuously learns and adapts to evolving customer preferences and market dynamics. By leveraging real-time feedback loops and reinforcement learning algorithms, businesses will be able to fine-tune their personalization strategies in response to changing trends, competitor actions, and customer feedback.
Conclusion
In conclusion, AI-powered personalization represents a paradigm shift in how businesses interact with their customers. By harnessing the power of machine learning and big data, companies can create tailored experiences that drive engagement, increase loyalty, and ultimately boost revenue. As technology continues to evolve, the potential for personalized experiences will only grow, ushering in a new era of customer-centricity in the digital age.
1 note
·
View note
Text
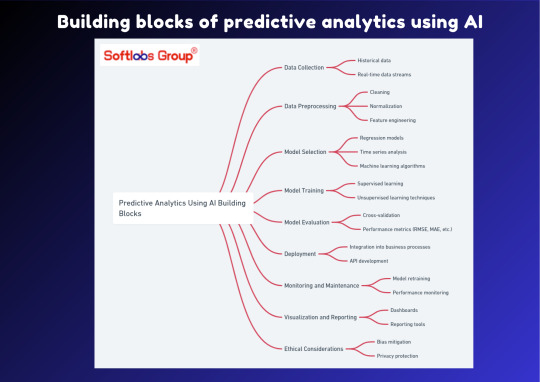
Explore the building blocks of predictive analytics using AI with our informative guide. This simplified overview breaks down the essential components that enable accurate forecasting and decision-making, empowering businesses to anticipate trends and make informed decisions. Perfect for those interested in leveraging AI for predictive insights. Stay informed with Softlabs Group for more insightful content on cutting-edge advancements in AI.
0 notes
Text
Elevate Your Data Game: Unleashing Potential with AI-Powered Data Preparation Software
In the era of rapid digital transformation, organizations are turning to AI-powered data preparation software to elevate their data game and unlock unprecedented insights. Traditional data preparation methods often fall short in handling the complexities of today's vast and varied datasets. Enter AI-powered data preparation, a revolutionary approach that harnesses the capabilities of artificial intelligence to streamline and enhance the entire data preparation process.

One of the key advantages of AI-powered data preparation is its ability to automate mundane and time-consuming tasks. Machine learning algorithms embedded in these tools learn from patterns in data, automating tasks such as cleaning, structuring, and transforming data with remarkable precision. This not only accelerates the data preparation timeline but also significantly reduces the risk of human error, ensuring the integrity and accuracy of the prepared datasets.
These advanced tools are designed to adapt to the evolving nature of data. They can handle diverse data sources, whether structured or unstructured and navigate through the intricacies of real-world data scenarios. This adaptability is crucial in today's data landscape, where information is generated at an unprecedented pace and in various formats.
AI-powered data preparation software goes beyond automation—it leverages predictive analytics to suggest transformations, imputations, and enrichment strategies. By understanding the context and relationships within the data, these tools intelligently recommend the most effective steps for optimal data preparation. This not only empowers data professionals but also democratizes the data preparation process, enabling users with varying levels of technical expertise to contribute meaningfully to the organization's data goals.
Moreover, these tools foster collaboration between data teams and business stakeholders. The intuitive interfaces of AI-powered data preparation software facilitate seamless communication, allowing business users to actively participate in the data preparation process. This collaboration bridges the gap between raw data and actionable insights, ensuring that decision-makers have access to high-quality, prepared data for informed decision-making.
AI-powered data preparation software is a game-changer in the data analytics landscape. By automating, adapting, and intelligently guiding the data preparation process, these tools empower organizations to unleash the full potential of their data. As businesses strive to stay ahead in a data-driven world, embracing AI-powered data preparation is not just a choice—it's a strategic imperative to thrive in the realm of data analytics.
#Data Preprocessing#What is data preparation#data preparation tool#Data preparation software#AI-powered data preparation software#data preparation in data science#data preparation process#data preparation and analysis#data preprocessing in machine learning
0 notes
Text
it is in times like these that it is helpful to remember that all of medical science that isn't like, infectious disease, but PARTICULARLY psychiatry is a bunch of fake ass idiots who dont know how to do science, and when you hear about it on tiktok, it's being reinterpreted through somebody even dumber who is lying to you for clicks. as such you should treat anything they say as lies.
u do this wiggle because it's a normal thing to do.
anyways i looked at this paper. they stick people (n=32) on a wii balance board for 30 seconds and check how much the center of gravity moves. for AHDH patients, it's 44.4 ± 9.0 cm (1 sigma) and for non ADHD patients its 39.5 ± 7.2 cm (1 sigma)
so like. at best the effect size is 'wow. adhd people shift their weight, on average, a tiny bit more than non-adhd people, when told to stand still'.
in summary, don't trust tiktok, and:


every once in a while i learn some wild new piece of information that explains years of behavior and reminds me that i will never truly understand everything about my ridiculous adhd brain
#they scan the brains also but 1) the effect is weak 2) the analysis isn't blinded at all so#i don't know enough about brain imaging but if it's anything like 2d image analysis#i could get whatever result you wanted at any strength by changing how i preprocess the data.#and frankly. the neuroscience psychiatry people don't give me a lot of hope that they know or understand that
60K notes
·
View notes
Text
#feature scaling#data normalization#machine learning#data preprocessing#ML techniques#quick insights#data science
2 notes
·
View notes
Text
finally went and started looking into nightshade because it sounds. dubious. apparently the project's full title is "nightshade: protecting copyright". it is absolutely wild that a bunch of internet communists saw that and went "yeah this is a good thing, we should totally rally around this"
#txt#copyright law hardly benefits individual artists.#it DOES benefit companies like disney‚ warner brothers‚ etc. that already have copyright over all the art they would ever need.#yknow ~the billionaires~ and ~the corporations~ y'all like to harp on about? that's them.#even if you think this endeavor is worth it.#this team does not have your best interests at heart.#anyway i say it's dubious bc#1. i am VERY skeptical of the idea that enough data will be 'poisoned' to make a difference#2. ive seen computer vision ppl point out that perturbations like nightshade's can be overridden with just basic preprocessing#(like resizing images) that scientists would be using before training anyway.#‘ai’
1 note
·
View note
Quote
I don't miss him anymore. Most of the time, anyway. I want to. I wish I could but unfortunately, it's true: time does heal. It will do so whether you like it or not, and there's nothing anyone can do about it. If you're not careful, time will take away everything that ever hurt you, everything you have ever lost, and replace it with knowledge. Time is a machine: it will convert your pain into experience. Raw data will be compiled, will be translated into a more comprehensible language. The individual events of your life will be transmuted into another substance called memory and in the mechanism something will be lost and you will never be able to reverse it, you will never again have the original moment back in its uncategorized, preprocessed state. It will force you to move on and you will not have a choice in the matter.
Charles Yu, How to Live Safely in a Science Fictional Universe
1K notes
·
View notes
Text
The curse has been lifted
So anyways i'm banned from my tablet until i finish my grant proposal and have 5 participants booked
#but now i have a cascade of participants to run#and another final draft of that grant proposal to complete#and i have to redo some of my analysis and put a poster together for a conference in april but the draft needs to be done early#and i have tutorials still ongoing and more students every day freaking out about their exams#about to get turbocharged once we declare that we're going on strike right as exams start#and i should also be writing two other papers#and i never actually finished the preprocessing of my pilot data i just got to good enough#and i have no food in my house and never sleep and i haven't called either of my parents in like a month and a half#so#well fuck might sit down and draw tomorrow anyways#still defective#holy shit and taxes are coming around the corner and i have to unfuck the financials for the study before i deal with my conference costs
3 notes
·
View notes
Text
"I've decided to ruin the data for chatbots mango pickle car is established novacain plumber isn't b52s"
welcome to the internet! allow us to introduce our friends! Our first friend is very loyal and has known us real well, we have always had to call him, when any kind of data happens, Mr. preprocessing. And Mr preprocessing has always been a bit of a nasty down for anything bottom slut, tbh, hooking up with every stack that has ever existed and doing whatever they need. He loves to serve. And He's recently found true love! this is his beautiful new open relationship husband, an LLM that returns the textblock if the textblock contains cogent textual data or a 1 if it's not. Usually they orgy with Mr. Sentiment Classification and Mr. Named Entity Extraction and Mr. Knowledge Graph, but lately, Mr. LLM has been going to the gym and that muscle daddy chaser Mr. preprocessing is so satisfied by his massive honkin bara tits and his fatass puffy textual data processing nipples that sometimes he doesn't even need mr sentiment classification and mr named entity extraction, because Mr. LLM is sewper into roleplay, so, he just pretends to be them sometimes, and Mr preprocessing finds that's really all it takes to make him squirt most of the time, so they can still text Mr Knowledge Graph (he's into watching) everything that's hot to him and zero things that aren't hot, and Mr Preprocessing and Mr LLM are actually debating proposing to Mr Knowledge Graph for the kinkiest 3 person marriage that has ever existed because they all share a cryptography and pattern recognition kink!
10 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
8 notes
·
View notes